
This post explains some of the not so well-known features and configurations settings of the Azure App Service deployment slots. These can be used to modify the swap logic as well as to improve the application availability during and after the swap. Here is what you can do with them:
- Swap slots only if the warm up request gets an expected status code
- Minimize the random cold starts in the production slot
- Configure the behavior of the slot settings
- Use swap detector to troubleshoot swap errors
Swap based on the status code
During the swap operation the site in the staging slot is warmed up by making an HTTP request to its root directory. More detailed explanation of that process is available at How to warm up Azure Web App during deployment slots swap. By default the swap will proceed as long as the site responds with any status code. However, if you prefer the swap to not proceed if the application fails to warm up then you can configure it by using these app settings:
WEBSITE_SWAP_WARMUP_PING_PATH: The path to make the warm up request to. Set this to a URL path that begins with a slash as the value. For example, “/warmup.php”. The default value is /.WEBSITE_SWAP_WARMUP_PING_STATUSES:Expected HTTP response codes for the warm-up operation. Set this to a comma-separated list of HTTP status codes. For example: “200,202” . If the returned status code is not in the list, the swap operation will not complete. By default, all response codes are valid.
You can mark those two app setting as “Slot Settings” which would make them remain with the slot during the swap. Or you can have them as “non-sticky” settings meaning that they would move with the site as it gets swapped between slots.
Minimize random cold starts
In some cases after the swap the web app in the production slot may restart later without any action taken by the app owner. This usually happens when the underlying storage infrastructure of Azure App Service undergoes some changes. When that happens the application will restart on all VMs at the same time which may result in a cold start and a high latency of the HTTP requests. While you cannot control the underlying storage events you can minimize the effect they have on your app in the production slot. Set this app setting on every slot of the app:
WEBSITE_ADD_SITENAME_BINDINGS_IN_APPHOST_CONFIG: setting this to “1” will prevent web app’s worker process and app domain from recycling when the App Service’s storage infrastructure gets reconfigured.
The only side effect this setting has is that it may cause problems when used with some Windows Communication Foundation (WCF) application. If you app does not use WCF then there is no downside of using this setting.
Control SLOT-sticky configuration
Originally when deployment slots functionality was released it did not properly handle some of the common site configuration settings during swap. For example if you configured IP restrictions on the production slot but did not configure that on the staging slot and then performed the swap you would have had the production slot without any IP restrictions configuration, while the staging slot had the IP restrictions enabled. That did not make much sense so the product team has fixed that. Now the following settings always remain with the slot:
- IP Restrictions
- Always On
- Protocol settings (Https Only, TLS version, client certificates)
- Diagnostic Log settings
- CORS
If however for any reason you need to revert to the old behavior of swapping these settings then you can add the app setting WEBSITE_OVERRIDE_PRESERVE_DEFAULT_STICKY_SLOT_SETTINGS to every slot of the app and set its value to “0” or “false”.
swap Diagnostics detector
If a swap operation did not complete successfully for any reason you can use the diagnostics detector to see what has happened during the swap operation and what caused it to fail. To get to it use the “Diagnose and solve problems” link in the portal:
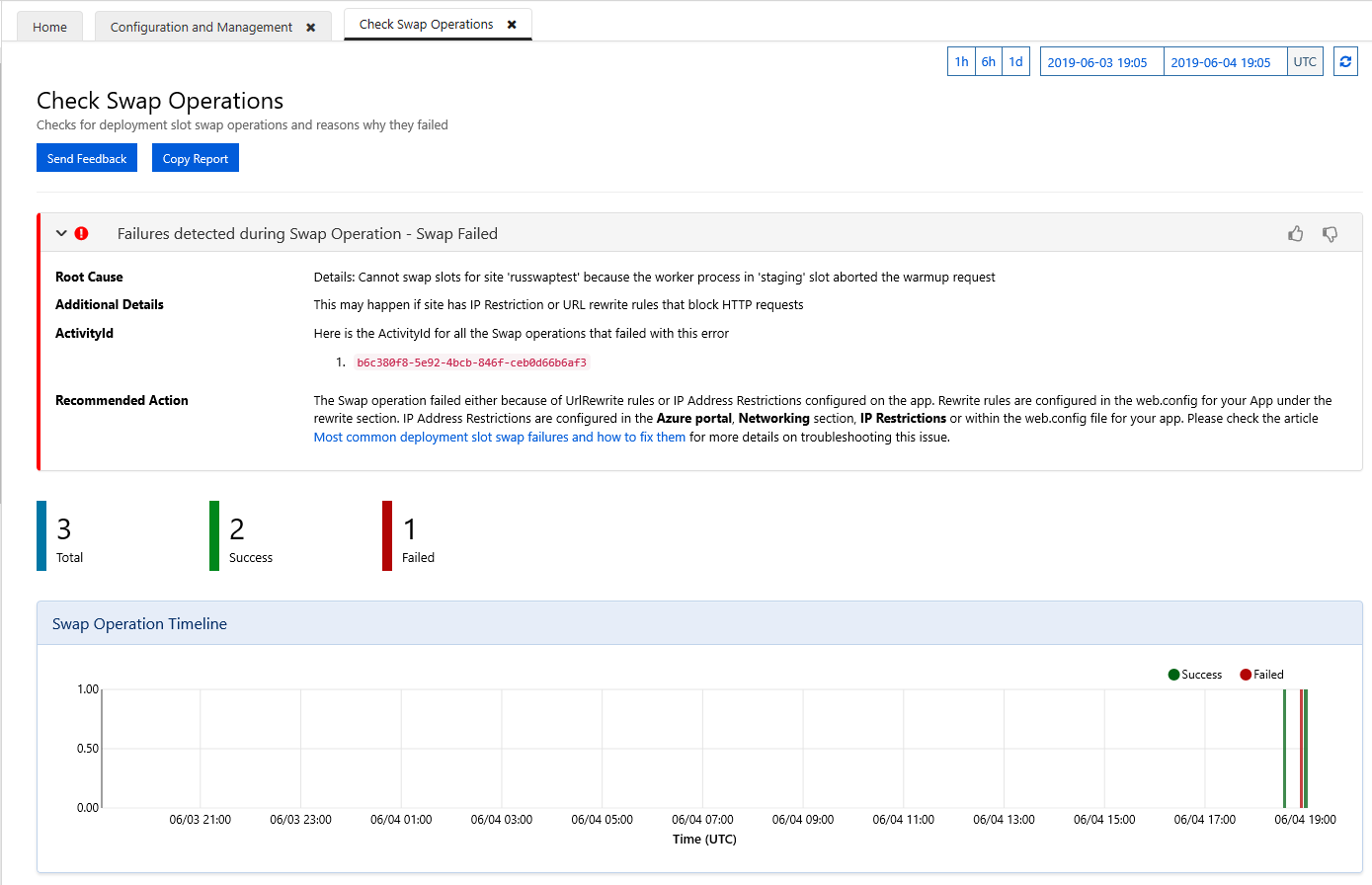
From there click on “Check Swap Operations” which will open a page showing all the swaps performed on the webapp and their results. It will include possible root causes for the failures and recommendations on how to fix them.
Just to explain the specifics of what WEBSITE_ADD_SITENAME_BINDINGS_IN_APPHOST_CONFIG app setting does. By default we put the site’s hostnames into the site’s applicationHost.config file “bindings” section. Then when the swap happens the hostnames in the applicationHost.config get out of sync with what the actual site’s hostnames are. That does not affect the app in anyway while it is running, but as soon as some storage event occurs, e.g. storage volume fail over, that discrepancy causes the worker process app domain to recycle. If you use this app setting then instead of the hostnames we will put the sitename into the “bindings” section of the appHost.config file. The sitename does not change during the swap so there will be no such discrepancy after the swap and hence there should not be a restart.
Thanks for the explanation. I would like to add that this setting is also fixing a cold restart of all instances the first time that you scale in/out after the swap. It took a while to us to identify that was the root cause…
Good article. I realized that every time I new hostnames, my web app automatically recycles.
Try to set WEBSITE_ADD_SITENAME_BINDINGS_IN_APPHOST_CONFIG=1 and see if the app still restarts after you add hostnames.
Hi,
Could you explain more about ” Then when the swap happens the hostnames in the applicationHost.config get out of sync with what the actual site’s hostnames are.”
It means applicationHost.config also is swapped and the applicationHost.config of stagging slot does not match with the production slot hostnames?
Thank you.
Correct, the applicationHost.config is also swapped. After the swap it has the staging slot’s hostnames in the “bindings” section even though the site is now in the production slot with production hostnames. That’s why it is recommended to use the above mentioned app setting so that no hostnames are placed in the “bindings” section at all.
Hi,
Could you tell more about
“The only side effect this setting has is that it may cause problems when used with some Windows Communication Foundation (WCF) application. If you app does not use WCF then there is no downside of using this setting.”
Why it affects?
Thank you.
Hi,
I found your post in the below topic
https://social.msdn.microsoft.com/Forums/azure/en-US/652bbf10-4f82-4993-b9f3-76543cce7482/wcf-applications-on-azure-appservice-fail-with-error-no-protocol-binding-matches-the-given-address?forum=windowsazurewebsitespreview
So we can prevent WCF issues by adding below setting?
Yes that’s correct.
So how does WEBSITE_SWAP_WARMUP_PING_PATH work together with a configured warmup in applicationInitialization? Will both warmups be fired and can it be any conflicts?
We are using scaling for our app services so I guess we still need the applicationInitialization warmup.
Hi Eric, did you ever find confirmation about this behaviour? We’re now having the same questions
“The only side effect this setting has is that it may cause problems when used with some Windows Communication Foundation (WCF) application. If you app does not use WCF then there is no downside of using this setting.” – this isn’t quite true:
If your app doesn’t host WCF services, then it is ok, Ie, web apps which consume a WCF can use this setting without issue, it is only an issue for web apps which host WCF services.
Adam, thanks for the correction.
Hi, thank you for the article
Could you please explain if the WEBSITE_SWAP_WARMUP_PING_PATH setting is in any way related to scaling out? In other words, if the new instance of the function app is added by automatic scale-out on Consumption plan, will WEBSITE_SWAP_WARMUP_PING_PATH be invoked before any requests are routed to it? How about AppService plan, e.g. P1v2?
Thank you
HI Yevgen, this app setting is not used during scale out. It is only used during deployment slot swap operation.
Hi Ruslan, thank you for the reply. Is there any way to make sure the new instances are warmed up during scale out before any new requests hit them?
With an App and its Slot set up in different App Service plans, is there any way to get the Slot to move to the App’s plan and the App to the Slot’s plan when swapped?
No, that is not supported. When a site is moved between App Service Plans it has to be re-provisioned on the VM’s of that App Service plan, which results in a cold start after the swap.
I am experimenting with new feature of Azure App service – Health Check https://github.com/projectkudu/kudu/wiki/Health-Check-(Preview).
According to my tests healthCheckPath is swapped (App Service version 86.0.7.153). This is not desirable. To use staging release one will have to set healthCheckPath to both production and staging slot. Setting healthCheckPath on staging slot will prevent site from being recycled when not used and releasing app service plan resources.
Please consider making healthCheckPath setting sticky as other settings you mention in CONTROL SLOT-STICKY CONFIGURATION.
Hi Alexander, thanks for letting me know about this! I will pass this suggestion to the development team.
Hi Alexander,
In this scenario, do you have Always On disabled on staging? Are you concerned that the health checker is pinging your staging site and keeping it from scaling down?
Hi Jason,
Yes, Always On is disabled on staging. We release new version of peek hours using slot swaps. During peek hours we would like for staging to go down (IIS app poll recycling due inactivity) and free App Service Plan memory.
Hi,
How do I deal with the “Always On” combined with “HTTPS only” issue in an Azure Appsetting?
See https://stackoverflow.com/questions/64097262/how-to-ignore-https-only-azure-appservice-custom-domain-setting-for-always-on
Appreciate the help
Hello Ferdi – i’ve replied on stackoverflow.
We have an app that needs two app settings to be slot settings. We deploy the new code to stage slot, when it’s checked we see the code changes, it’s all fine. We then swap and the new code is production and we can see the new code, it’s all fine. When we check the now stage slot for a few seconds it doesn’t have the new code change (We expect this and this is what we want, the old code to roll back if needed) but then after a few seconds, the now stage slot with the old code restarts and has the new code (same ad prod slot).
This means there is no longer a way to rollback to the previous prod state if we wanted to. My understanding of this is because of the two sticky slot app settings, it sees it as a change and does a restart. We’re using linux app service and a docker container btw.
Does this basically mean if you need to use slot settings in the app config, you can never benefit from rolling back in an emergency?
Thanks
Hello Joss, thanks for contacting me about this.
Normally, after the swap the staging slot should have the code that used to be in production and it would remain there until you deploy or make changes to it. The goal is exactly as you’ve said – to be able to roll back and put it back into production in case of an emergency. That’s the current behavior of swap for regular windows app services. I would expect that this would be the same for linux app services with docker containers, but sounds like that’s not the case. I’ll check this with the development team to confirm if this is expected.
Hi Ruslan – we’re trying to migrate off of a cloud service classic deployment to app services and I’m finding the fact that the slots share the same resource to be almost impossible to work with.
Specifically – we see that whenever we do a swap the CPU goes real high while it does the warmup and as a result the production workload’s response times go almost 10x slower!
I see lots of discussion but no resolution anywhere on this – do you recommend production apps that need to keep response time in check during deployments stay on cloud services?
Hi Raavi,
It is possible to move the slots to different app service plans. That way the production and staging slot will run on different VMs and will not interfere with each other.
Here is the explanation how to move an app to a different app service plan. The same steps apply to slots.
Move an app to another App Service plan
Ruslan – Had no idea that was possible, actually I searched for a while looking for this exact solution.
Don’t think it’s mentioned anywhere. Def warrants getting added to the article!
Yes, BUT… When we later on swap staging with production, then I guess that the APP Service Plan meant for staging will go into production? So if i move all my staging slots to an App Service Plan with less power, and maybe just running 1 instance… Then after swap to production, the App Service plan with less power and one(1) instance will be the production App Service Plan.. Isn’t that the way it works? Kind of the loadbalancer will just change the traffic to the apps currently on staging VM’s/App Service Plan? Or?